Quelle solution de scraping utiliser pour les médias en ligne ?
L’internet est la plus vaste source d’information et de données jamais construite par l’humanité. L’exploitation automatique de cette énorme collecte de données est extrêmement difficile sans connaissance à priori sur la structure de chaque site. Un processus automatisé tel que la classification de données, l’extraction de mots clés ou la recherche de documents nécessite un outil de scraping efficace. Dans nos travaux antérieurs, nous avons effectué une étude comparative entre les différents outils de scraping existants.
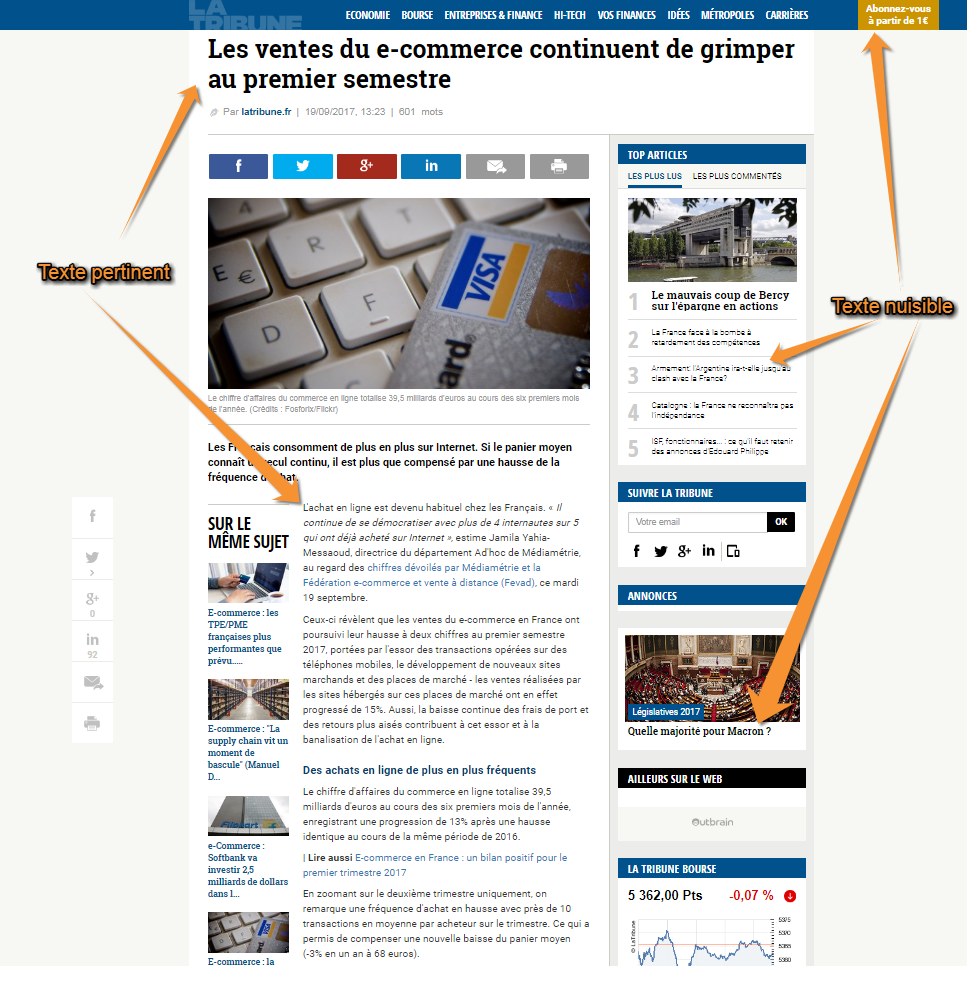
Chez Press’ Innov, nous avons ressenti le besoin de développer un outil de scraping plus précis pour répondre notamment au métier de la Presse. L’imprécision de certaines solutions existantes de scraping est dûe à plusieurs informations nuisibles qui impactent négativement la qualité du service rendu.
Pour rappel, cette étude ne concerne que les scrapers ne disposant d’aucune connaissance à priori de la structure des sites à scraper. Ils doivent agir de manière totalement autonome, sans intervention humaine. Ceux qui ne fonctionnent qu’à partir d’une connaissance pré-requise du site sont des “Text Extractor”. Nous allons donc être un peu plus ambitieux que cela …!
Un nouvel outil de scraping
Avant tout apprentissage, il est incontournable de comprendre la nature des textes à traiter. Les informations intra-pages (ex: longueur de mot, densité de lien, etc) utilisées par les outils de scraping classiques tels que Boilerpipe, DiffBot et Goose sont souvent insuffisantes. Nous rencontrons de plus en plus des sites dynamiques avec des contenus de longueurs variables. Des menus d’actualité et des publicités avec des caractéristiques proches de celles du contenu principal de la page (voir la capture ci-dessus). A ce stade, la distinction entre les deux types d’information (nuisible et pertinente) devient extrêmement compliquée.
L’utilisation des informations inter-pages pour chaque site est une dimension informationnellement très porteuse. L’évolution des informations nuisibles d’une page à l’autre permet d’extraire des patterns utilisés dans la prédiction des informations indésirables.
En se basant sur cette logique, nos data scientists ont développé un nouvel outil de scraping basé sur des techniques d’intelligence artificielle. Nous avons appliqué des techniques d’apprentissage sur des données à large échelle, issues de plusieurs sites hétérogènes afin d’extraire les patterns discriminants. Notre outil de scraping a été renforcé par des méthodes statistiques ainsi par que quelques règles d’inférence.
La précision, le rappel et les performances de notre scraper ont été comparés avec d’autres solutions du marché. Des améliorations significatives ont été apportées pour nos cas d’utilisation. Grâce à ces efforts, Press’ Innov dispose de son propre scraper.
Une architecture parallèle en temps-réel
La scalabilité et la distribution sont deux clés importantes pour la qualité d’un service temps-réel. La mise à jour régulière de nos services d’apprentissage nécessite une architecture optimisée. Pour ce faire, notre équipe de développement a mis en place une solution basée sur un calcul parallèle avec une gestion intelligente de cache assurant des performances optimales.
Nous sommes très satisfaits du résultat. Les métiers que nous adressons sont à l’affût de cette qualité. Nous avons déjà plusieurs idées de solutions innovantes autour de cette technologie !
Ce sujet vous intéresse ?