Les biais en machine learning : les données d’entraînement
Le machine learning en quelques mots
Le machine learning est une branche de l’intelligence artificielle qui consiste à entraîner une machine à exécuter des tâches automatiquement.
Pour cela, les données d’entraînement doivent être nombreuses et variées. Le ou les mêmes types de tâches sont soumis plusieurs fois au modèle, et ce sont ces boucles d’entraînement qui lui permettent d’en tirer ses propres règles et d’affiner ses prédictions.
Ce genre de modèle est utilisé dans un grand nombre de secteurs d’activités : la pharmacologique, l’industrie et la presse en ligne, par exemple.
Le choix des données d’entraînement d’un modèle de machine learning
Construire un modèle de machine learning efficace requiert des données pertinentes pour l’entraîner avant de le tester. Quelle importance accorder au choix des données utilisées lors de cet entraînement ?
Entraîner un modèle à reconnaître les noms de ville
Pour le comprendre, prenons l’exemple d’un modèle de machine learning entraîné pour détecter des noms de villes dans du texte. De façon schématique, les données d’entraînement peuvent être représentées ainsi :

À l’issue de l’entraînement, le modèle devrait être capable de détecter les noms de ville lorsqu’il en rencontre dans un texte. Voyons alors les prédictions du modèle lors du test :
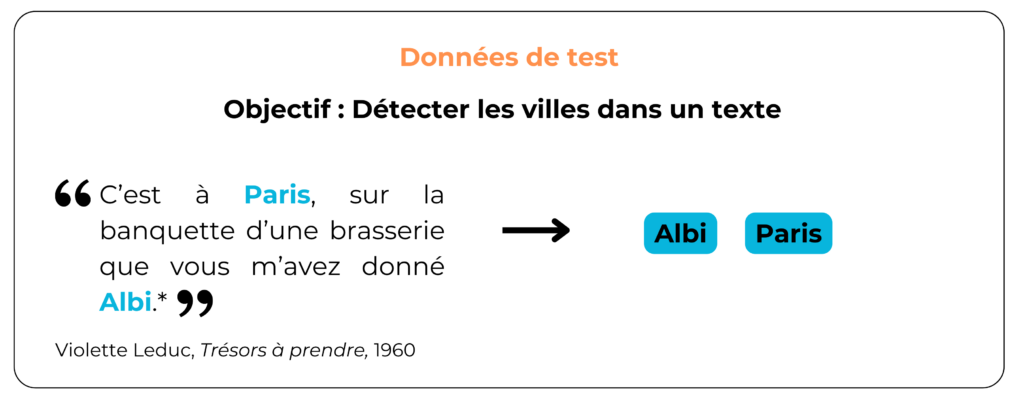
En fin de compte, le modèle semble fonctionner, et permet de détecter des noms de ville dans les textes. Est-ce vraiment le cas ?
Distinguer les villes des autres noms propres
Pour s’assurer que le modèle est capable de détecter tous les noms de villes qu’il rencontre, varions les données test. Par exemple, que se passe-t-il si les données comportent d’autres types de noms propres :
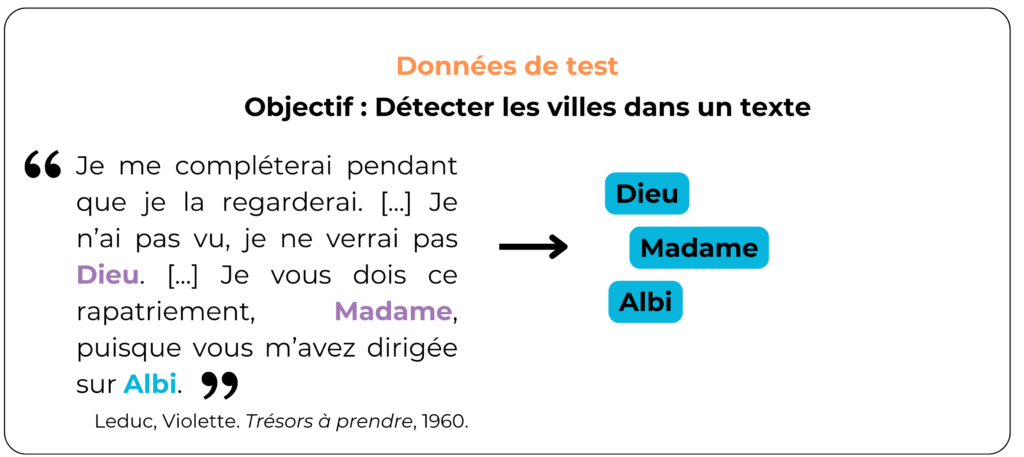
Ici, on s’aperçoit que le modèle ne dissocie pas les villes des autres noms propres. Cela peut poser problème si des données qui comportent un nom de famille, ou encore de pays, lui sont soumises. En l’état, le modèle semble avoir assimilé que si un mot débute par une majuscule, il s’agit sûrement d’une ville. C’est pourquoi il aurait dû rencontrer une diversité de noms propres pour mieux distinguer spécifiquement les villes.
Reconnaître les villes avec un nom composé
Voyons maintenant comment le modèle gère les noms de ville composés étant donné que les données d’entraînement n’en comportaient pas :
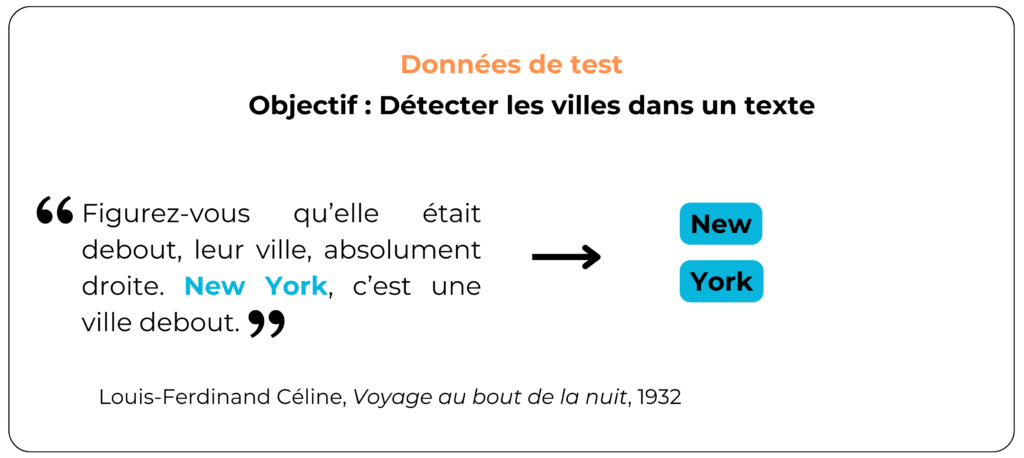
Le modèle ne reconnaît pas la ville de New York mais prédit à la place les villes New et York. Ainsi, d’autres noms composés de villes comme “Le Havre”, “Saint-Étienne”, ou encore “Annecy-le-Vieux” ne seront probablement pas détectés par le modèle. Pour éviter ce problème, le modèle doit être entraîné sur des données qui incluent des noms de villes variés : simples, composés, et avec des tirets ou non.
Détecter les villes dans tous les types de texte
Enfin, les données d’entraînement utilisées sont toutes issues d’œuvres littéraires. Ce manque de diversité peut limiter la capacité d’un modèle à reconnaître des noms de villes dans d’autres types de textes comme un bulletin météo, un avis en ligne ou encore un article scientifique. Que se passe-t-il lorsque le modèle rencontre un tweet ?
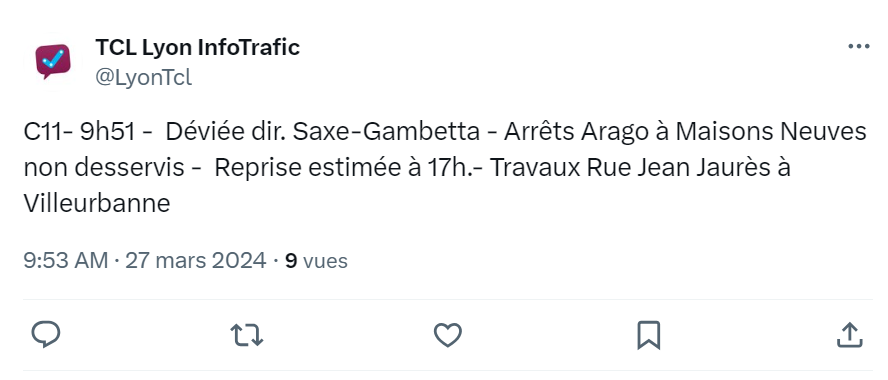
Dans cet exemple, le modèle ne peut pas se baser sur le contexte : la ponctuation est manquante, il ne s’agit pas réellement de phrases, et certains mots sont abrégés. Tous ces éléments l’empêchent de détecter le nom de la ville de Villeurbanne.
Il est donc essentiel de confronter le modèle à plusieurs types de textes, et à des registres de langage variés lors de l’entraînement.
Pour conclure, plusieurs bonnes pratiques permettent de faire en sorte que les modèles de machine learning soient performants. L’une d’entre elles consiste à utiliser des données variées, suffisamment nombreuses et cohérentes avec la tâche pour laquelle est programmée le modèle, afin de minimiser le risque d’y introduire des biais.
Ce sujet vous intéresse ?