Bias in machine learning: training data
Machine learning in a nutshell
Machine learning is a branch of artificial intelligence that involves training a machine to perform tasks automatically.
To achieve this, the training data must be numerous and varied. The same type(s) of task are submitted to the model several times, and it is these training loops that enable it to derive its own rules andrefine its predictions.
This type of model is used in a wide range of sectors: pharmaceuticals, industry and the online press, for example.
Choosing training data for a machine learning model
Building an effective machine learning model requires relevant data to train it before testing it. How important is the choice of data used for training?
Train a model to recognize city names
To understand this, let's take the example of a machine learning model trained to detect city names in text. Schematically, the training data can be represented as follows:

At the end of training, the model should be able to detect city names when it encounters them in a text. Let's take a look at the model's test predictions:
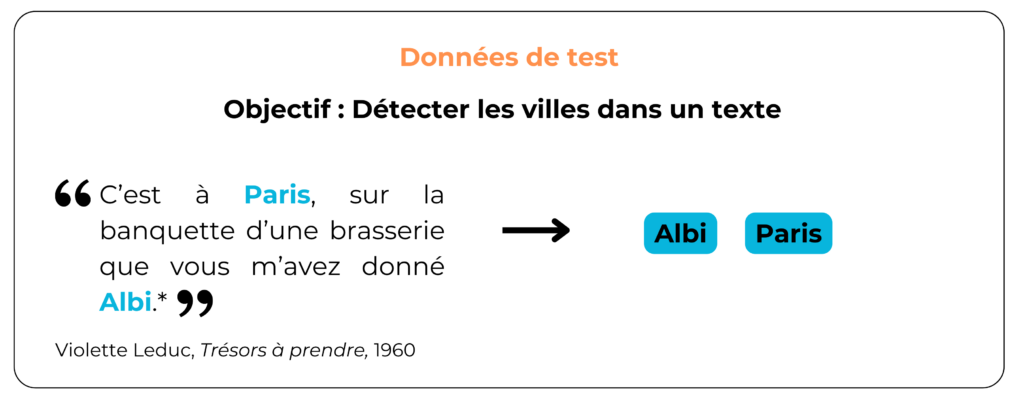
In the end, the model seems to work, and allows us to detect city names in texts. Is this really the case?
Distinguishing cities from other proper nouns
To ensure that the model is able to detect all the city names it encounters, let's vary the test data. For example, what if the data includes other types of proper names:
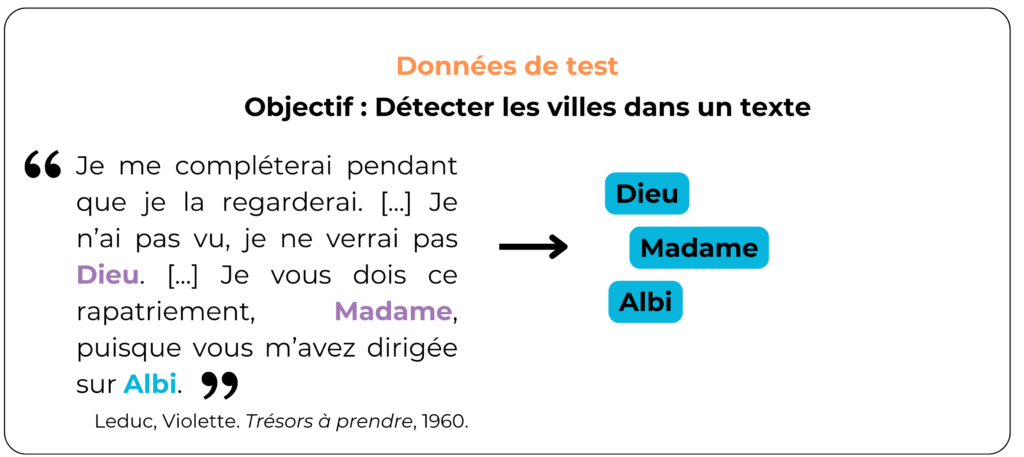
Here, we can see that the model doesn't separate cities from other proper nouns. This can be a problem if data containing a surname or country name is submitted. As it stands, the model seems to have assimilated that if a word begins with a capital letter, it must be a city. This is why it should have encountered a variety of proper nouns to better distinguish cities specifically.
Recognizing cities with compound nouns
Now let's see how the model handles compound city names, given that the training data didn't include any:
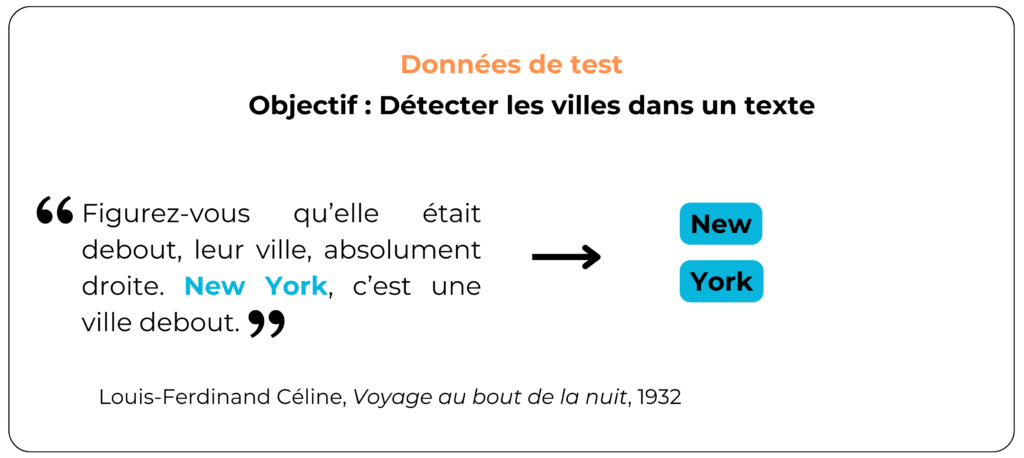
The model does not recognize the city of New York, but instead predicts the cities New and York. Thus, other compound city names such as "Le Havre", "Saint-Étienne", or "Annecy-le-Vieux" are unlikely to be detected by the model. To avoid this problem, the model should be trained on data that includes a variety of city names: simple, compound, and with or without hyphens.
Detect cities in all types of text
Finally, the training data used are all taken from literary works. This lack of diversity may limit a model's ability to recognize city names in other types of text, such as a weather report, an online review or a scientific article. What happens when the model encounters a tweet?
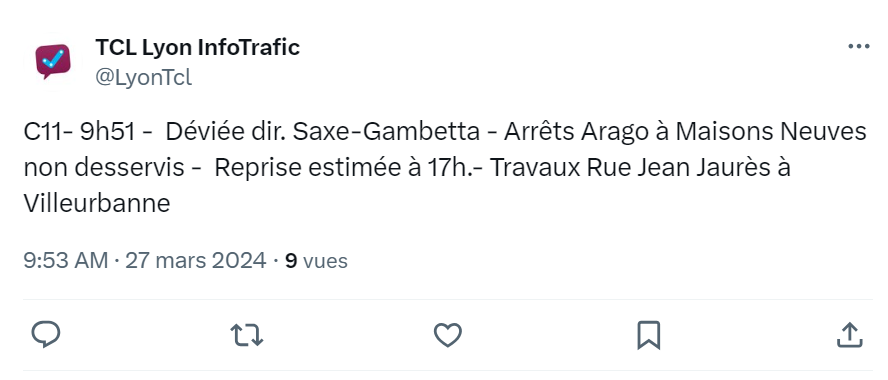
In this example, the model can't rely on context: punctuation is missing, sentences aren't really sentences, and some words are abbreviated. All these elements prevent it from detecting the name of the city of Villeurbanne.
It is therefore essential to confront the model with several types of text, and a variety of language registers during training.
In conclusion, several best practices to ensure that machine learning models perform well. One of these is to use a variety of data, sufficiently numerous and consistent with the task for which the model is programmed, in order to minimize the risk of introducing biases.
Are you interested in this topic?