Which algorithm to follow the buzz effect on social networks?
News' Innov offers its users an analysis of media coverage. Thanks to the various graphs in the application, it is possible to follow the evolution of the popularity of news topics.
For this analysis to be coherent and interesting, the data entered must be systematically updated.
Some data may change temporarily and differently over time for different items. Since we cannot control this evolution, what is the best solution to adopt in order to efficiently retrieve the new values of these data?
Example: the case of social indicators in a media web article.
![]()
Don't miss the Buzz!
The values of these indicators are retrieved by querying the various social network web services and providing the link to the media article's web page. News' Innov analyses a growing number of articles every day. The problem is to know how often to retrieve the new values of the social indicators in an efficient way without being blocked from accessing the web services of Facebook, Twitter and Google+?
Generally, within 10 minutes of the publication of an article, it is possible to see the values of the various social indicators on Facebook, Twitter and Google+ increase, double or even explode in the event of a buzz. But this evolution, however important, is ephemeral because 24 hours after the publication of the article in question, the values of the social indicators will be unchanged. Interest will be focused on another article.
So what is the best solution to effectively recover these values?
-
Update on demand? When the user accesses the graphs page, the data is automatically updated:
→ This is not an option, if this data is useful for other sections such as the News' Innov Top 10, this update will result in more updates for related data to keep the statistics consistent. The on-demand update is therefore growing and we risk taking too long to post a statistic information.
-
Sending data retrieval requests at a constant interval?
- Not wishing to miss any increase, they interview at very short intervals?
→ large number of unnecessary requests, being blocked from accessing the social network's web service due to an over-request for information and saturating the production server due to the large number of articles involved.
-
- Do we avoid overloading and interview at distant intervals?
→ our data is not up to date and therefore obsolete
-
- Are we interviewing at reasonable intervals?
→ our data is up to date but we miss the buzz!
- A hierarchy is established between the different media according to which one is best placed to publish articles that can create a buzz and each one is given a corresponding frequency of questioning?
→ Quite a complex and risky strategy, as a little-known media outlet may be able to make a buzz-inducing article exclusive.
We propose a solution that will allow any article from any media to have a powerful refresh of this data as close as possible to a real time refresh without overloading the social networks' web services.
General idea To find out how long it will take to refresh the values of the social indicators, we will use our previous recorded values, specifically the last three. From these three values we can determine a trend and guess the fourth value according to expectation criteria (how long before the value of the social indicator increases by 1? by 15? by 100? by 10% etc.).
Step 1: Initialization
We do not yet have the values of the social indicators of an article that has just been published... no choice, we query at a constant initial interval until we reach three. These will be our first three coordinates that we can place on a graph with the time of the query execution on the x-axis and the social indicator values on the y-axis.
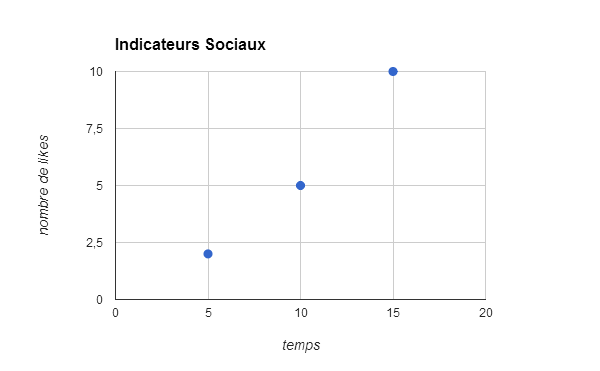
Step 2: Determine the trend of increasing social indicators
From these three points, we will be able to determine a trend line and thus predict the next value.
Example: we have 3 points:
- after 5 minutes: 2 Facebook "likes
- after 10 minutes: 5 Facebook "likes
- after 15 minutes: 10 Facebook "likes
Or The following system can be derived from this:
→ Polynomial :
To determine the polynomial, several methods are available such as the Gauss pivot, the determinant, Lagrangian interpolation etc...
From this polynomial we can determine the next value, for example after 20 minutes: Facebook "likes".
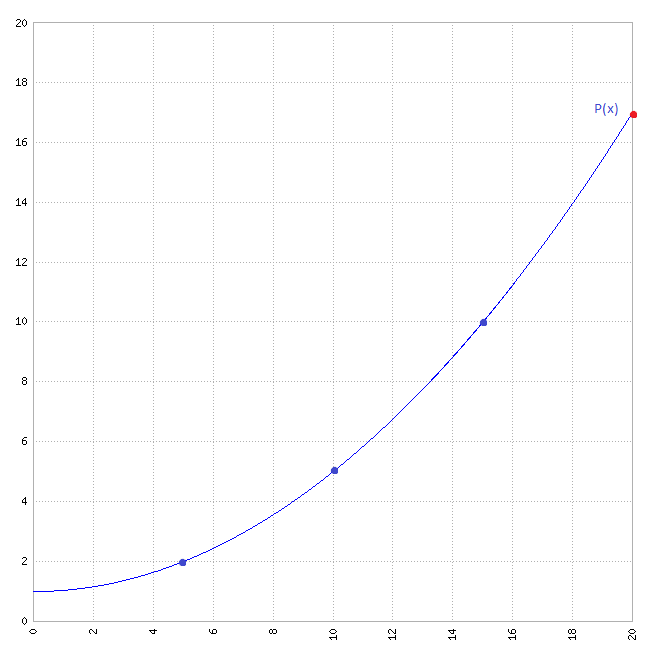
Third step: calculation by the tangent to the curve
The growth curve of the social indicators is strictly increasing, but the polynomial that is deduced is a parabola and can show decreases.
To avoid this kind of error, we will always base ourselves on the tangent to this polynomial. Once this curve has been drawn, we will be able to determine graphically how long it will take for our article to register 5 new Facebook "likes":
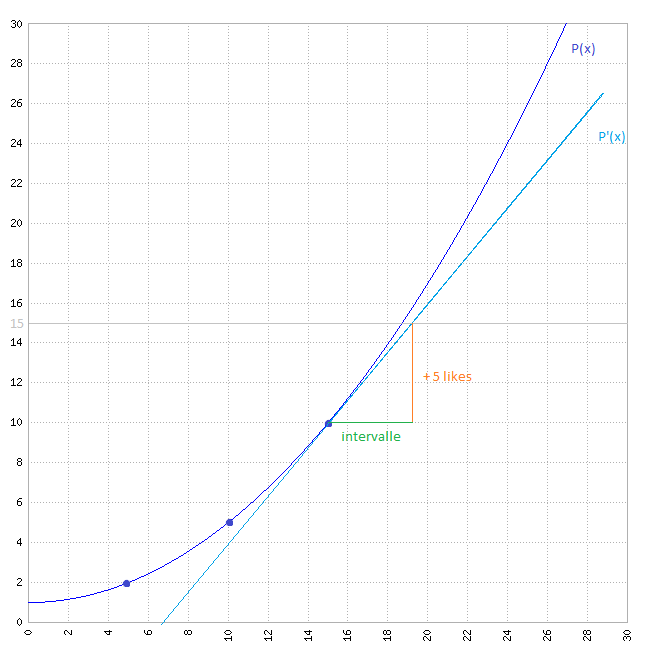
Graphically, the article should have registered 5 additional Facebook "likes" 4 minutes after the last registration.
To find the interval by calculation: we use the method of extrapolation by the tangent to the curve.
This method is effective because it tells us how long it will take to query the web service again, so we don't have to query unnecessarily. Thus, the space left by articles that cause unnecessary queries allows other more popular articles to be queried more frequently than others. In addition, this method adapts to expectations and constraints because we can vary the expectation criteria such as increasing the number of Facebook "likes" expected for more distant query frequencies or reducing it for a shorter interval frequency.
What has been gained?
This efficient updating of indicators allows News 'Innov :
- to display up-to-date data,
- to respect the limits of use of the web services of social networks,
- reduce the large number of unnecessary queries for the benefit of articles requiring more frequent queries.
Feel free to judge for yourself on News' Innov!
Are you interested in this topic?