Automate press article categorization with continuous learning
Rubrication, or categorization of press articles, consists of classifying articles into different thematic groups.
Generally speaking, it's the editors who take charge of assigning them a category. This practice is conducive to natural referencing, internal linking and reader navigation of the website.
However, the sheer volume of content published every day on a press site can make it difficult to manually carry out all the semantic enrichments required for proper indexing, of which heading is one. This increases the risk of errors, which can be detrimental to the visibility and traffic capture of a press site.
Continuous learning to automate the layout of news articles
Today, certain language models canautomate article categorization through semantic content analysis.
However, headings are bound to evolve over time, and new categories may appear. It is therefore necessary to find a way for the model to take these evolutions into account, while maintaining the relevance of its predictions.
One solution could be to re-train the model on the entire data set, including the new category: this is known as global learning. Unfortunately, this is a very costly and time-consuming process.
A less costly alternative would be to use continuous learning, which consists of an iteration of smaller training sessions . As each training session consists of as little data as possible, it is much less energy-intensive than global learning.
To assess the effectiveness of different learning techniques, we first need to know the performance of theglobal learning method. This will provide a benchmark against whichcontinuous learning techniques can be compared.
Global learning: fine-tuning newspaper articles
Briefly, the fine-tuning consists in specializing a language model by making it perform well on a specific and precise task, such as the layout of newspaper articles. Although it can achieve very good results, it is a costly technique in terms of data and computational resources.
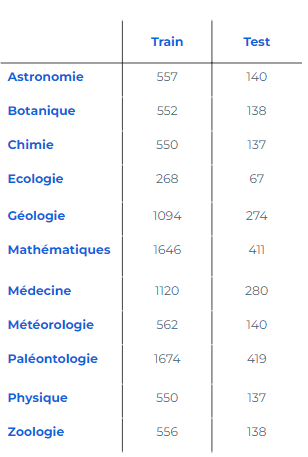
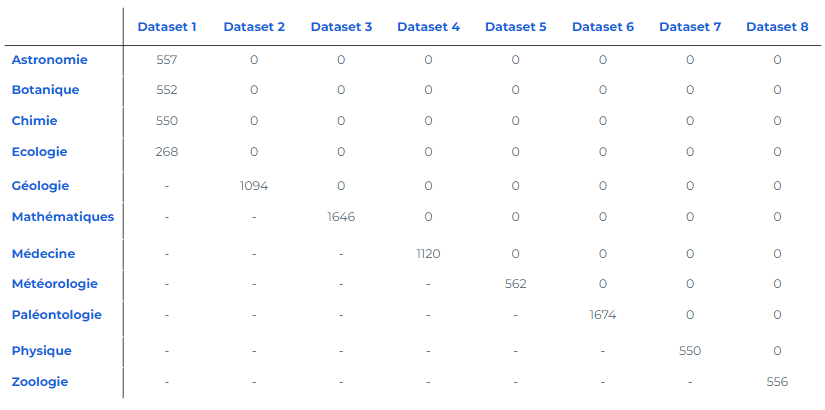
Let's test fine-tuning with a dataset consisting of 11,410 press articles, to be assigned to just one of the eleven existing categories below.
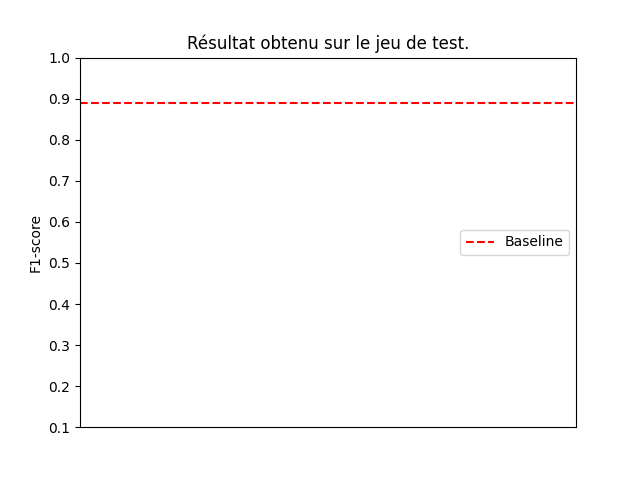
The model training includes 80% of the dataset, and the remaining 20% was used for testing. The score obtained on the test set is 0.89.
In the end, this global learning is efficient, but it requires several thousand articles and numerous computing resources. Continuous learning is a less costly technique, but does it deliver equally good results?
Continuous learning: successive fine-tuning and representative sampling
Successive fine-tuning
Successive fine-tuning consists of using several different data sets to adapt the model, for example to changes in the editorial line of a newspaper title, or the addition of a new category.
Here, the model has already been trained to classify articles in "Astronomy", "Botany", "Chemistry" and "Ecology" using the first dataset. The second dataset only contains articles in the "Geology" category. The aim is to adjust the model so that it can predict this new category.
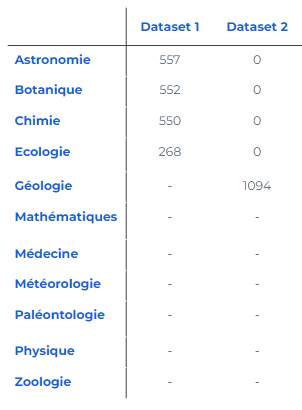
As new categories are added, the datasets will always consist exclusively of articles corresponding to the new heading.
The result is a score of 0.18 for this continuous learning method.
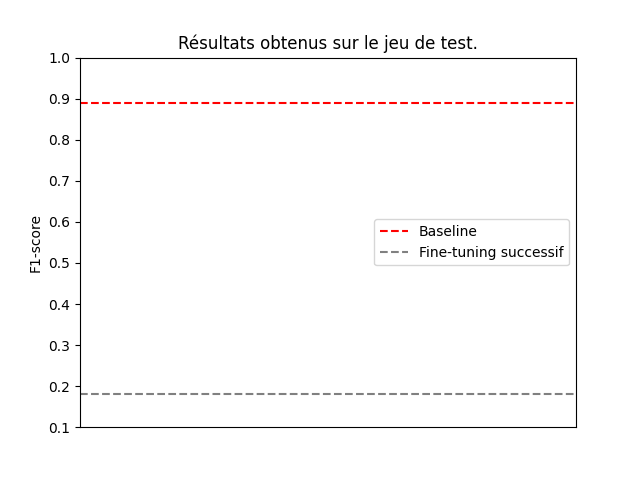
Far from achieving the desired result, this method doesn 't seem to allow for efficient and effective rubrication of press articles. Indeed, it seems that the model's performance deteriorates when the new training data does not contain all the prediction possibilities: this is the phenomenon ofcatastrophic forgetting, where the model has forgotten the knowledge it previously had. It seems, therefore, that examples of the other categories are missing from the dataset.
Representative sampling
Representative sampling requires first selecting a panel of articles to be included in the datasets. These must be the most relevant, so that the model can be based on them for training purposes. The advantage of taking the most representative is to limit the number of articles per topic already learned, and thussave costs and resources.
To obtain the best possible sample, it is necessary to calculate the plunges of all items belonging to the same category using the language model. Here's a schematic representation:
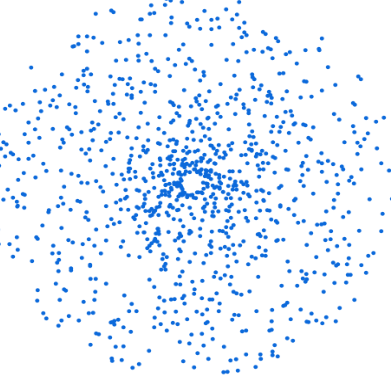
Next, calculate the centroid (in red below), i.e. the mean point on all dimensions:
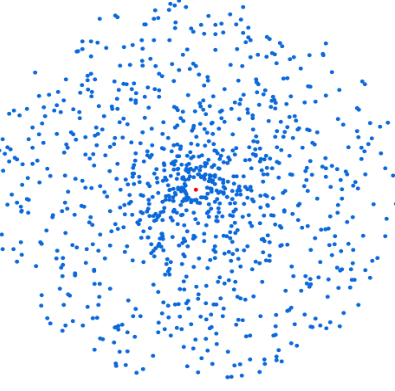
The K items closest to the centroid (in cyan blue below) are identified using a cosine similarity. These are the items that will be selected for the representative sample:
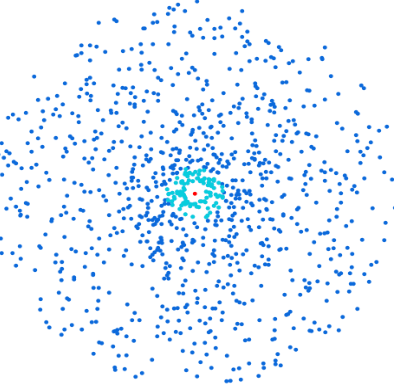
For each new training session, the dataset is made up of a batch of items belonging to the new category to be predicted, as well as thesample of the K most representative items from each category.
As a result, the higher the K number, the higher the score of this representative sampling method, reaching 0.82.
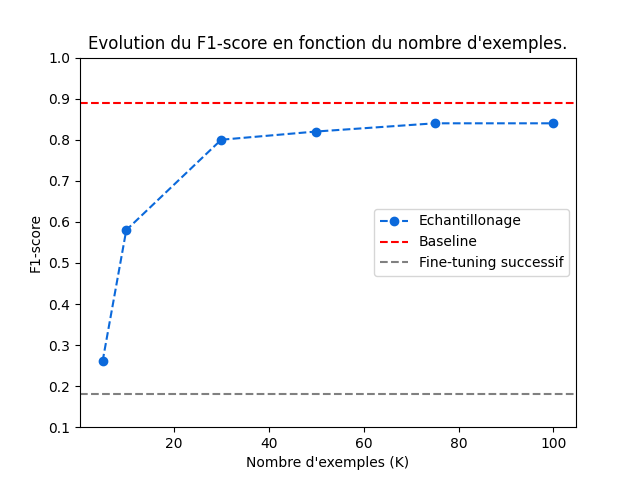
However, the score reaches a plateau of efficiency around 70 articles, which reduces the size of the dataset andsaves on modelresources and processing time .
Finally, although global learning is the most efficient method, less costly techniques can achieve comparable results, such asrepresentative sampling. In addition, it offers the possibility ofadapting the model to changes in the editorial line, or to the addition of new categories.
Are you interested in this topic?