Big Data: MapReduce for real time
As part of the NewsInnov project, we needed to find a method of calculating statistics in "near" real time on large volumes of data.
Having chosen MongoDB as our database, our research quickly led us to two data aggregation methods: MapReduce and AggregationFramework. A first study shows us that AggregationFramework seems faster than MapReduce and is easier to learn. Going a little further in the comparison, it turns out that MapReduce can manage data aggregation in an incremental way (delta of modified data only), and is therefore faster than AggregationFramework which is in "Full" mode. To conclude this small comparison, MapReduce brings us more flexibility by giving the possibility to customise the results of a data aggregation.
We therefore chose MapReduce, which better suited our needs.
Let's see how we used it on a concrete dataset to generate statistics in "near" real time. The tools you need :
-
RoboMongo - which is a very good client. It is a good compromise between a graphical interface and MongoDB command execution.
A. Example of Data
We give here a set of data that will follow us throughout our discussion. This data is simple, but it will be used to expose many of the technical points we have faced in using MapReduce.
The data can be loaded in RoboMongo by copying the JSON code below into the insertion field of a document.
{"name" : "Tim", "country" : "USA", "age" : 15}
{"name" : "Sandra", "country" : "USA", "age" : 18}
{"name" : "Alex", "country" : "France", "age" : 19}
{"name" : "Zhong", "country" : "Taiwan", "age" : 19}
{"name" : "Tom", "country" : "USA", "age" : 20}
{"name" : "Marc", "country" : "France", "age" : 20}
{"name" : "Hao", "country" : "Taiwan", "age" : 12}
{"name" : "Jennifer","country" : "USA", "age" : 15}
{"name" : "Jean", "country" : "France", "age" : 17}
{"name" : "James", "country" : "USA", "age" : 17}
{"name" : "Peter", "country" : "USA", "age" : 20}
{"name" : "Jorge", "country" : "Portugal", "age" : 20}
B. Creating the MapReduce Script
Here is a first script to count the number of people with the same age. MapReduce has a Map function to group our data on a criterion and a Reduce function to aggregate our data.
function(){ return db.Data.mapReduce( Fonction MAP function(){ emit(this.age,{count:1}); }, Fonction REDUCE function(key,values){ var reduced = {count:0}; values.forEach(function(val) { reduced.count+=val.count; }); return reduced; }, Configurations { out : 'Stats' }); }
This script consists of two functions and a configuration object. The first function is the Map function. It specifies that the grouping of elements must be done on the basis of age and then associates a count field with each element.
function(){ emit(this.age,{count:1}); }
The second function has two parameters. Key corresponds to the age on which the grouping was made, values corresponds to the set of associated values.
Fonction REDUCE function(key,values){ var reduced = {count:0}; Pour chaque valeur associé à l’age key values.forEach(function(val) { On additionne les valeurs des précédent reduce reduced.count+=val.count; }); return reduced; }
The reduced variable corresponds to the reduced data returned by the function. When executing a MapReduce Job, it is important to have the same model here as in the Map function. Although it is not very obvious at first, any MapReduce Job execution is already incremental, we see in the example Fig. 1 that reduce is called twice: the first call to reduce groups the people with 20 years old in pairs. The second call to reduce groups the 20 year olds again. This is why reduce cannot simply make a
reduced.count++;
but must add the previous value.
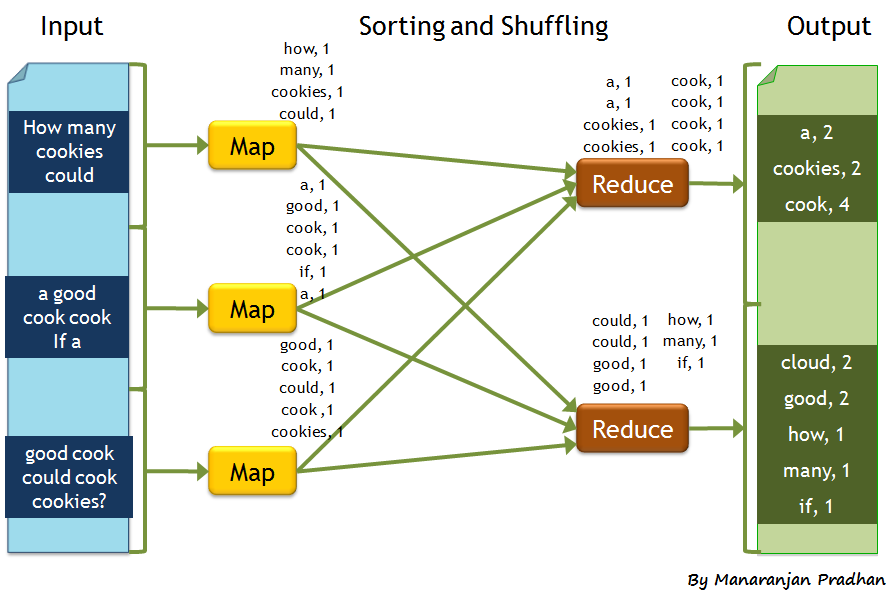
Fig. 1 Example of a MapReduce job execution
This diagram shows us the call to the map function and then the call to the Reduce function. The number of calls to the Reduce function depends on the data, the distribution of the data on the servers, we have no control over it.
C. Full or Incremental?
In order to handle incrementality in MapReduce we need to add an insertionTime field that will give us the time the element was inserted. In our MapReduce job the query field pre-selects the items to be processed. By specifying only new documents, we can incrementally manage the addition of documents to our aggregated collection. We replace the string in the out field with an object with a reduce field.
function(from,to){ return db.Data.mapReduce( function(){ emit(this.age,{count:1}); }, function(key,values){ var reduced = {count:0}; values.forEach(function(val) { reduced.count+=val.count; }); return reduced; }, { query: { insertionTime : { $gt: from, $lte: to} }, out : {reduce:'Stats'} }); }
However, we need to store in a file or another collection the last inserted document that was taken into account during the last MapReduce run.
D. A more substantial example
I promised you an example with a complex model and here I am giving you a sum. Now let's see a more complicated example. Let's suppose that we want to have the list of names of the people grouped in addition to the age grouping
function(){ return db.Data.mapReduce( function(){ emit(this.age,{count:1, names: [this.name]}); }, function(key,values){ var reduced = {count:0, names:[]}; values.forEach(function(val) { reduced.count+=val.count; for (var index in val.names){ reduced.names.push(val.names[index]); } }); return reduced; }, { out : 'Stats' }); }
This gives us the following result:
{
"_id" : 12,
"value" : {
"count" : 1,
"names" : ["Hao"]
}
}
{
"_id" : 15,
"value" : {
"count" : 2,
"names" : ["Tim","Jennifer"]
}
}
{
"_id" : 17,
"value" : {
"count" : 2,
"names" : ["Jean","James"]
}
}
{
"_id" : 18,
"value" : {
"count" : 1,
"names" : ["Sandra"]
}
}
{
"_id" : 19,
"value" : {
"count" : 2,
"names" : ["Alex","Zhong"]
}
}
{
"_id" : 20,
"value" : {
"count" : 4,
"names" : ["Tom", "Marc", "Peter", "Jorge"]
}
}
This example is very similar to the previous one the difference is that we add a names field to the Map function, which is a vector of names. At startup each element is initialized with an array of a single element which is the value of their own name attribute.
In the reduce, value.names contains an array of names. Each value in this array must be added to the values in the reduce.names field.
E. A little further towards the limits
Now imagine that we want to group people by age and for each age we have the list of names, the list of countries and for each country we have the distribution, i.e. how many people are from one country or another.
The problem addressed here is the problem of double aggregation. At present such double aggregation is difficult. We therefore recommend the use of a hash table. We recall here that each of the scripts written here can be written incrementally by adding the " reduce " and the insertion date. Adding an element to our collection will not force us to recalculate everything.
function(){ return db.Data.mapReduce( function(){ var countriesRep = {}; countriesRep[this.country] = 1; emit(this.age,{count:1, names: [this.name], countries : countriesRep}); }, function(key,values){ var reduced = {count:0, names:[], countries: {}}; values.forEach(function(val) { reduced.count+=val.count; for (var index in val.names){ reduced.names.push(val.names[index]); } for (var key in val.countries){ if (!reduced.countries.hasOwnProperty(key)) { reduced.countries[key]=0; } reduced.countries[key] += val.countries[key]; } }); return reduced; }, { out : 'Stats' }); }
In theemit we initialise our table with the countries as key and a counter as value. At startup, each document has its country with a counter initialized to one. We must then in the reduce add the countries of the elements in the value. Keeping in mind that the counter can have a value greater than 1 at any time in the process. It cannot therefore be envisaged to do a
reduced.countries[key]++;
but a
reduced.countries[key]+=val.countries[key];
Here is the result we get after running the MapReduce Job:
{
"_id" : 12,
"value" : {
"count" : 1,
"names" : ["Hao"],
"countries" : {"Taiwan" : 1}
}
}
{
"_id" : 15,
"value" : {
"count" : 2,
"names" : ["Tim","Jennifer"],
"countries" : {"USA" : 2}
}
}
{
"_id" : 17,
"value" : {
"count" : 2,
"names" : ["Jean","James"],
"countries" : {"France" : 1,"USA" : 1}
}
}
{
"_id" : 18,
"value" : {
"count" : 1,
"names" : ["Sandra"],
"countries" : {"USA" : 1}
}
}
{
"_id" : 19,
"value" : {
"count" : 2,
"names" : ["Alex","Zhong"],
"countries" : {"France" : 1,"Taiwan" : 1}
}
}
{
"_id" : 20,
"value" : {
"count" : 4,
"names" : ["Tom","Marc","Peter","Jorge"],
"countries" : {"USA" : 2,"France" : 1,"Portugal" : 1}
}
}
To conclude
In the context of our project, our need was to perform real time on large volumes of data. Between AggregationFramework and MapReduce, we finally opted for MapReduce.
After testing it from different angles (different statistics), we are very satisfied with it. And despite the evolution of our requirements and needs, it continues to satisfy them.
Are you interested in this topic?